 tetoblog
tetoblog 
本記事は単回帰分析について、優しく解説しています。単回帰分析は機械学習の中でも極めて重要です。単に単回帰分析の用語を理解するだけではなく、Pythonで実際にコードを書くことでグッと理解が深まると思います。
本記事の内容
単回帰分析とは
単回帰分析とは、機械学習を行う上で非常に重要な分析方法です。
下に載せた動画が、単回帰分析について非常にわかりやすく解説していますので御覧ください。
12分と長いですが、8分くらいからの再生でも理解できるかと思います。
いかがでしたか。
動画の通り、単回帰分析とは、最小二乗法を利用してデータの中心を通る直線(回帰直線)を決め、回帰直線から未知のデータを予測するする方法です。
今回は、Pythonのパッケージを利用して1文で回帰直線を求めます。
単回帰分析のPythonによる実装
実装要件
今回は、身長(height)と体重(weight)のデータを用いて回帰分析を行います。
今回の要件として、
・回帰直線(y=ax+b)の「a」「b」を求め、図に直線を表示する
・データを元に、y = ax + bの「a」と「b」の値を求める
データの準備
25名分の身長(height)と体重(weight)の、csvデータを準備しました。
僕が適当に作ったデータですが、利用したい方は下のダウンロードボタンからどうぞ。
このcsvファイルを、
この後記述するPythonコードと同じディレクトリへ保存しておきましょう。
データを「matplotlib」でプロットさせてみるとこんな感じ。
横軸が身長、縦軸が体重です。
適当に作りましたが、良い感じの相関関係があって嬉しい。
全て表示させると、下のようなでデータです。
height weight
0 156 51
1 143 47
2 172 65
3 180 77
4 176 62
5 175 59
6 145 47
7 162 51
8 175 53
9 186 64
10 140 48
11 167 50
12 142 40
13 154 48
14 145 39
15 175 62
16 165 47
17 172 58
18 176 65
19 178 70
20 182 71
21 179 68
22 187 67
23 164 46ライブラリのインストール
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegressionさっそく、Pythonで実装していきます。
必要なライブラリは3種類です。
1行目の「pandas」はcsvファイルデータの読み込みに利用します。
2行目の「matplotlib」は図の作成と表示に利用します。
回帰分析で非常に重要なのが、3行目。
「scikit-learn(サイキット・ラーン)」とは、Pythonの機械学習ライブラリです。
回帰直線を求める際はscikit-learnを利用することが一般的なので、今回も利用します。
データの読み込み
df = pd.read_csv('sample.csv')
x = df[['height']]
y = df[['weight']]上記のコードで保存したcsvファイル(sample.csv)を「df」の変数へ格納します。
格納したデータを、
heightはx軸の値として、weightはy軸の値として、更に格納します。
線形回帰モデルのインスタンス化と学習
model = LinearRegression()
model.fit(x,y)この2行で回帰直線が求まります。
1行目でモデルを求めるためにインスタンス化。
2行目で、データxとyの値を引数に、一発でモデルを求めてくれます。
2行目の作業を「学習させる」とも言い換えができます。
ここでいうモデルとは、回帰分析で求められるy=ax+bのことで回帰直線とも言いかえられます。
あとは、これを図で表示するだけです。
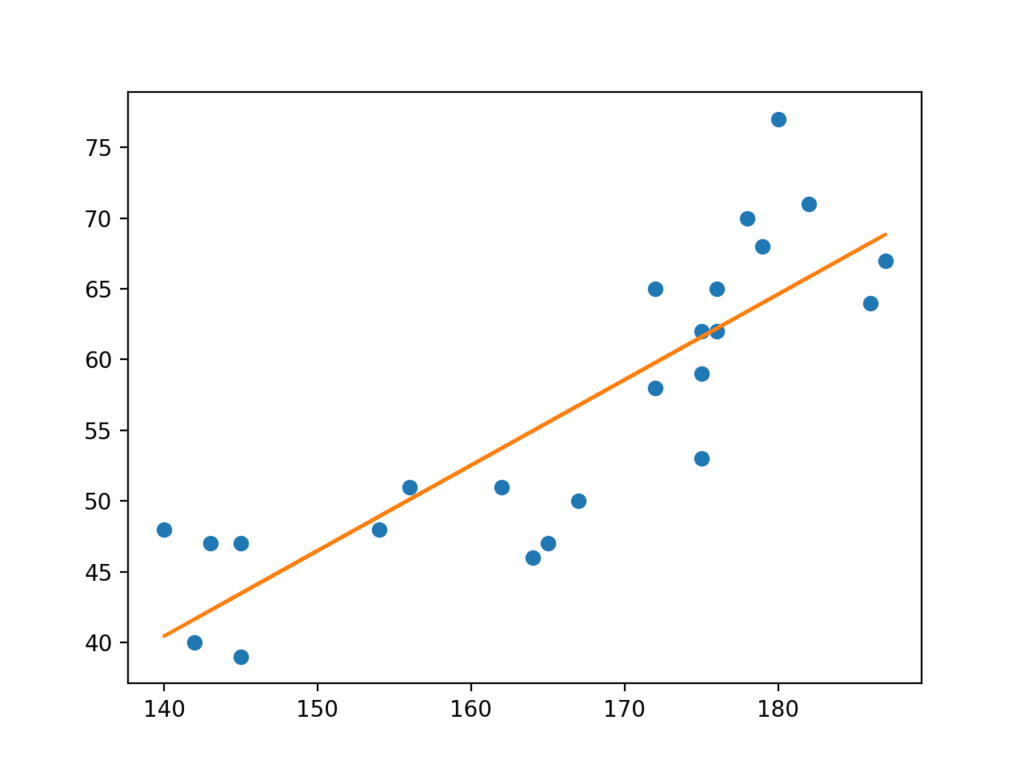
回帰直線をグラフで表示
plt.plot(x,y,'o')
plt.plot(x,model.predict(x))
plt.show()1行目のは、xとyの値を点でプロットさせる、という意味です。
2行目で、図に直線で表示ささせれば、下の画像のような図が完成します。
aの値とbの値を表示
print('a = ', model.coef_)
print('b = ', model.intercept_) 【実行結果】
a = [[0.60418319]]
b = [-44.13816746]y=ax+bの「a」と「b」の値は「coef_」と「intercept_」の属性に格納されています。
実行結果の値から回帰直線は、
y = 0.60418319x -44.13816746
ということがわかります。
この直線を利用して、50kg の人の体重予想とかも一発です。
全コード
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
df = pd.read_csv('sample.csv')
x = df[['height']]
y = df[['weight']]
model = LinearRegression()
model.fit(x,y)
plt.plot(x,y,'o')
plt.plot(x,model.predict(x))
plt.show()
print('a = ', model.coef_)
print('b = ', model.intercept_)ということで、本記事は単回帰分析について、Pythonのコードを使用しながら紹介しました。
最後まで読んでいただき、ありがとうございました\(^o^)/

前略
大変興味ある記事でしたので写経してみましたが、次のようなエラーが出ました。
ValueError: Expected 2D array, got 1D array instead:
array=[156 143 172 180 176 175 145 162 175 186 140 167 142 154 145 175 165 172
176 178 182 179 187 164].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample
このエラーはどのように解消すればいいのでしょうか。
石堂正美さん
コメントありがとうございます…!
エラー文も載せて頂いている点、大変助かりました。ありがとうございます。
このエラーはsklearnでfit()が呼ばれたときに出るエラーだと思われます。
なので、サンプルコードでいうと11行目までで何かが起こっていると判断できます。
僕の推測ですが、サンプルコード内7, 8行目の
x = df[[‘height’]]
y = df[[‘weight’]]
を、下記のように写し間違えている可能性は無いでしょうか。
x = df[‘height’]
y = df[‘weight’]
参考に、下記の記事も参考になるかもしれません。
https://aiacademy.jp/media/?p=2126